Quando criança, Luis von Ahn imaginou uma academia onde, em vez de se cobrar mensalidade, a energia gerada pelo esforço físico das pessoas fosse vendida a companhias elétricas.
Hoje, como professor de ciência da computação na Universidade Carnegie Mellon e empresário, von Ahn não perdeu a ideia de vista.
Ele é o homem por trás dos projetos reCaptcha, o sistema de verificação que exige que digitemos os caracteres em uma imagem, e Duolingo, um programa de ensino de idiomas gratuito, ambos com o objetivo de “traduzir a web inteira”.

Luis von Ahn, professor de ciência da computação e empresário (Foto: Divulgação)
No Duolingo, materiais que precisam ser traduzidos são fragmentados e distribuídos entre os exercícios dados aos alunos. Quando o documento estiver completamente traduzido, é devolvido ao dono, que paga pela tradução (clientes como a Wikipédia recebem o serviço de graça).
No caso do reCaptcha, as imagens de letras distorcidas são trechos de livros e documentos mal reconhecidos por scanners no processo de digitalização, de modo que, ao digitá-los, o usuário “contribui” para a digitalização de livros e documentos.
A verificação de ambos é baseada no crowdsourcing, ou seja, na contribuição de várias pessoas que digitam a mesma imagem –ou fazem o mesmo exercício– e geram um padrão de erros e acertos.
Luis von Ahn também foi o primeiro a usar o termo “computação humana”, que descreve a combinação entre habilidades exclusivamente humanas e a capacidade de processamento dos computadores.
A Folha o entrevistou durante o evento WWW2013, que aconteceu no mês passado no Rio.
Folha – O que é computação humana e por que ela o fascina?
Luis von Ahn – Existem coisas que computadores não podem fazer, mas seres humanos podem. Seres humanos conseguem decifrar o conteúdo de imagens, mas computadores não. Seres humanos traduzem textos melhor que o computador. Isso é a computação humana, uma questão de eficiência e reutilização das coisas.
Você disse que precisamos traduzir toda a web. Por que é mais difícil fazer isso em algumas línguas que em outras?
A desigualdade é imensa. Mais de 50% da web é em inglês, mas menos de 25% das pessoas que usam a web falam inglês. Para os computadores, a dificuldade das línguas depende da quantidade de informação que existe. Então inglês é relativamente fácil porque há muitos dados, enquanto línguas com menos dados são mais difíceis.
Projetos como o Duolingo podem ter impacto positivo na educação em países em desenvolvimento?
A maioria dos métodos de aprendizado de línguas exige que você tenha dinheiro, e a maioria das pessoas que quer aprender não tem. Eu queria inventar um jeito de ensinar línguas de graça, em que a energia mental das pessoas fosse usada para fazer algo de valor: traduzir a web. A CNN pagava tradutores profissionais para traduzir seu site, e agora paga a nós.
Cobramos de algumas empresas para traduzir, então de certa maneira eles estão pagando para que pessoas aprendam línguas. Eles nos pagam, e damos às pessoas o ensino de graça.
Como você desenvolveu o método do Duolingo?
Há três anos, não sabíamos nada sobre o ensino de línguas. Então lemos alguns livros e fomos atrás de especialistas. Agora que temos 1 milhão de usuários, fazemos tudo com base nos dados. Por exemplo, se quero saber se devo ensinar adjetivos antes dos advérbios, metade dos próximos 50 mil usuários vai aprender em uma ordem, e a outra metade em outra ordem. Aí medimos qual grupo teve melhores resultados. O método é totalmente baseado em dados, estatística, e não em uma filosofia.
Observamos muitas coisas com esses experimentos. Por exemplo: notamos um leve decréscimo no desempenho de pessoas com 20 anos em relação a pessoas de 10. Também descobrimos que mulheres italianas aprendem inglês 10% mais rápido que homens italianos, mas não tenho ideia do porquê.
A quantidade de dados de que dispomos hoje e a capacidade de processá-los podem mudar o modo como fazemos ciência?
Acredito que sim. Há 20 anos, o ensino de língua funcionava com um professor e 20 alunos. Não dá para saber muito sobre como ensinar melhor com 20 alunos, porque 20 é pouco. Talvez depois de 20 anos você possa inferir algo. Agora, podemos observar 2 milhões de pessoas aprendendo uma língua ao mesmo tempo e conseguimos entender as coisas em horas, em vez de anos. O cientista tenta entender, e o engenheiro só tenta fazer. No meu caso, estou tentando fazer, mais do que entender.
Quais você acha que são as limitações dessa abordagem via dados hoje e amanhã?
Sempre que fazemos uma mudança no Duolingo, fazemos dois tipos de testes. Um deles é experimentar com 1% dos usuários para ver o desempenho. Não descobrimos as razões, só descobrimos o que funciona melhor. O outro teste que fazemos é trazer pessoas até o laboratório para observar se preferem o botão à esquerda ou à direita. Isso é em uma escala bem pequena, com cinco usuários em vez de 50 mil, mas ajuda a descobrir os porquês de muitas coisas. Essa é a diferença: a abordagem via dados é uma caixa preta, não dá para saber os porquês.
Gostaria de ouvir seus comentários sobre o uso que spammers têm feito do crowdsourcing para quebrar Captchas em sites de download ou pornografia, por exemplo.
O que eles fazem é pagar gente para digitar Captchas o dia inteiro, sem escreverem um programa ou um código para fazer isso. Assim eles conseguem acesso ao que o Captcha esteja protegendo, como contas do Facebook. Então cada vez que alguém na Índia digita um Captcha, os spammers ganham uma conta de Facebook que são usadas pra mandar spam.
RAIO-X
LUIS VON AHN
IDADE E ORIGEM
34 anos, Guatemala
FORMAÇÃO
PhD em ciência da computação pela Universidade Carnegie Mellon
CARREIRA
Começou a pesquisar criptografia em 2000, com os Captchas, que previnem fraudes. Criou o ESP Game, licenciado pelo Google para melhorar a busca de imagens. Fundou o reCaptcha (recaptcha.net), uma atualização do Captcha, e o Duolingo (duolingo.com), programa de ensino de línguas que acaba de ganhar versão para Android. É também professor de ciência da computação na Universidade Carnegie Mellon
Fonte: Folha de S. Paulo
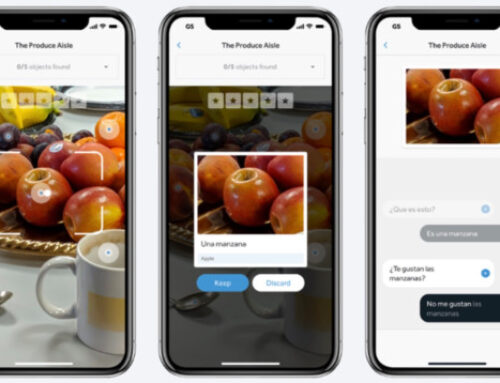
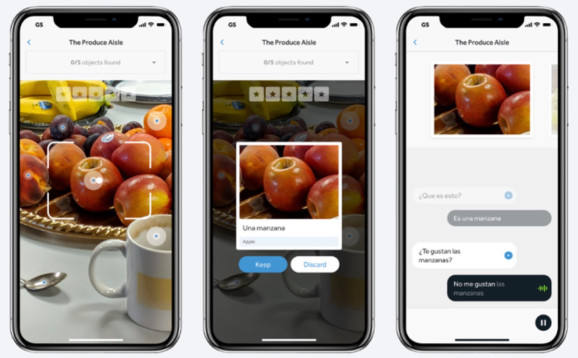{kind=link}
Leave A Comment
You must be logged in to post a comment.